
 GitHub - matloff/R-vs.-Python-for-Data-Science
GitHub - matloff/R-vs.-Python-for-Data-Science
Hello! This Web page is aimed at shedding some light on the perennial R-vs.-Python debates in the Data Science community. This is largely (though not exclusively) a debate between the Statistics (R) and Computer Science (Python) fields. Since I have a foot in both camps (I was a founding member of both the Statistics and Computer Science Departments at UC Davis), I hope to shed some useful light o

 R 4.1で入ると噂の|>が開発版のRに入ったので触ってみた。 - Technically, technophobic.
R 4.1で入ると噂の|>が開発版のRに入ったので触ってみた。 - Technically, technophobic.

 WebサービスのA/Bテスト代替手段としての観察データからの平均処置効果推定 - LIVESENSE Data Analytics Blog
WebサービスのA/Bテスト代替手段としての観察データからの平均処置効果推定 - LIVESENSE Data Analytics Blog

 陸田青享 - 作画@wiki
陸田青享 - 作画@wiki
 "install.packages()"するのはこれが最後!Rのパッケージ管理には「pacman」を使おう - Qiita
"install.packages()"するのはこれが最後!Rのパッケージ管理には「pacman」を使おう - Qiita

 4 RStudioでパッケージをインストールする | 初心者向けRのインストールガイド
4 RStudioでパッケージをインストールする | 初心者向けRのインストールガイド
 デジタルツインとは | IBM
デジタルツインとは | IBM

 ヒシアケボノでかすぎとは [単語記事] - ニコニコ大百科
ヒシアケボノでかすぎとは [単語記事] - ニコニコ大百科
![ヒシアケボノでかすぎとは [単語記事] - ニコニコ大百科](https://cdn-ak-scissors.b.st-hatena.com/image/square/5bd1fac8d544d19340796767c18bdf23d7d3493d/height=288;version=1;width=512/https%3A%2F%2Fdic.nicovideo.jp%2Fimg%2Fog_b.jpg)
 コメくいてー顔
コメくいてー顔

 VARモデル補遺(備忘録) - 渋谷駅前で働くデータサイエンティストのブログ
VARモデル補遺(備忘録) - 渋谷駅前で働くデータサイエンティストのブログ

 Rでtweetをテキストマイニング:ワードクラウドと共起ネットワーク - 医療職からデータサイエンティストへ
Rでtweetをテキストマイニング:ワードクラウドと共起ネットワーク - 医療職からデータサイエンティストへ

 RPubs - その無茶振り,(Rで)GISが解決します
RPubs - その無茶振り,(Rで)GISが解決します
 R ユーザーのための Pandas 実践ガイド II: siuba と datar - ill-identified diary
R ユーザーのための Pandas 実践ガイド II: siuba と datar - ill-identified diary

 線形混合モデルとその応用例 - Qiita
線形混合モデルとその応用例 - Qiita

 岩波データサイエンスvol.3のCM接触の因果効果を他の方法で推定してみた(2) - YuRAN-HIKO
岩波データサイエンスvol.3のCM接触の因果効果を他の方法で推定してみた(2) - YuRAN-HIKO

 これをやるだけで上位1%になれるRプログラミングのTIPS
これをやるだけで上位1%になれるRプログラミングのTIPS

 HCI研究者の心理統計ノート
HCI研究者の心理統計ノート

 XGBoostとLightGBMの違い - DATAFLUCT Tech Blog
XGBoostとLightGBMの違い - DATAFLUCT Tech Blog

 R 文字列ベクトルで文字列を指定して要素を削除する方法 | トライフィールズ
R 文字列ベクトルで文字列を指定して要素を削除する方法 | トライフィールズ
 Data Science for Psychologists
Data Science for Psychologists

 Accelerate your plots with ggforce
Accelerate your plots with ggforce
 Rを使ったデータ処理
Rを使ったデータ処理
 オンラインで実施できるアイスブレイク30選!自己紹介系・ゲーム系など | 謎解きコンシェルジュ
オンラインで実施できるアイスブレイク30選!自己紹介系・ゲーム系など | 謎解きコンシェルジュ

 R言語でクラスタリングしてみた - Qiita
R言語でクラスタリングしてみた - Qiita

 R言語でトピックモデルとクラスタリング - からっぽのしょこ
R言語でトピックモデルとクラスタリング - からっぽのしょこ

 Rのデータサイエンス書籍相関図(R初学者用)をつくってみた。 - Qiita
Rのデータサイエンス書籍相関図(R初学者用)をつくってみた。 - Qiita

 R のパッケージ {targets} にコントリビュートした話 - Sansan Tech Blog
R のパッケージ {targets} にコントリビュートした話 - Sansan Tech Blog

 「大規模計算時代の統計推論」 を全部Rでやってみる ~第2章~ - kur0cky
「大規模計算時代の統計推論」 を全部Rでやってみる ~第2章~ - kur0cky
 【ぼざろ】ぼっちと喜多ちゃんの関係性と原作比較、カットシーン
【ぼざろ】ぼっちと喜多ちゃんの関係性と原作比較、カットシーン

 Hedgehog will eat all your bugs
Hedgehog will eat all your bugs
 4.13 Convert models to equations | R Markdown Cookbook
4.13 Convert models to equations | R Markdown Cookbook

 JACKPOT108: Daftar Situs Judi Slot Online Slot88 Gacor Jackpot Terbesar
JACKPOT108: Daftar Situs Judi Slot Online Slot88 Gacor Jackpot Terbesar
 Rにおける代入演算子"<-"と"="の違い - Qiita
Rにおける代入演算子"<-"と"="の違い - Qiita

 『Rによる原因を推論する』
『Rによる原因を推論する』
 Jaehyun Song, Ph.D.
Jaehyun Song, Ph.D.

 Lambda Web Adapterでplumberを動かす - Qiita
Lambda Web Adapterでplumberを動かす - Qiita

 ブラウザで動くR、WebRが熱い!
ブラウザで動くR、WebRが熱い!

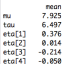 Stanをインストールするときのエトセトラ
Stanをインストールするときのエトセトラ

 Vector Autoregressive Model (VAR) using R | R-bloggers
Vector Autoregressive Model (VAR) using R | R-bloggers

 tSNEであそんでみた - ノンコーディングRNAネオタクソノミ
tSNEであそんでみた - ノンコーディングRNAネオタクソノミ


