










この解説記事、解説だと思って読むと、サラッととんでもない新事実が書かれてる。1面スクープ並みの新事案発生じゃないの? https://t.co/4khOA7rsya https://t.co/TsLmEkT6LN

 Hiromitsu Takagi on Twitter: "この解説記事、解説だと思って読むと、サラッととんでもない新事実が書かれてる。1面スクープ並みの新事案発生じゃないの? https://t.co/4khOA7rsya https://t.co/TsLmEkT6LN"
Hiromitsu Takagi on Twitter: "この解説記事、解説だと思って読むと、サラッととんでもない新事実が書かれてる。1面スクープ並みの新事案発生じゃないの? https://t.co/4khOA7rsya https://t.co/TsLmEkT6LN"
この解説記事、解説だと思って読むと、サラッととんでもない新事実が書かれてる。1面スクープ並みの新事案発生じゃないの? https://t.co/4khOA7rsya https://t.co/TsLmEkT6LN
Google Lensでテキストをスキャン いきなりですが、グーグルクローム関連の小ネタを3つ紹介。 Google Lensでテキストをスキャン 二窓検索機能 タブ検索 まず一つ目は、 現実世界にある文字・テキストを スマホのGoogle Lensのアプリで読み取り文字起こしして、 PCのGoogle Chromeに飛ばすというライフハック。 パソコンで作業してるときけっこう使えます。 まずはグーグルレンズで文字を読み込み、 場所・範囲を選択。 そして 上記画像の下部に「パソコンにコピー」ってあるのわかりますかね?? これをタップすれば、Google Chromeにコピーされ、 あとは PC上でCtrl+V コピペできるようになります。 例として上記画像の、サンタナのアルバム『キャラバンサライ』ライナーノーツから。 肉体は溶けて宇宙に変わる 宇宙は溶けて静寂の音に変わる 音は溶けてまばゆい

どうも、 株式会社Progate で SoftwareEngineer チームのマネージャーをしています @satetsu888 です。本記事は Progate AdventCalendar 2020 10日目です。 普段仕事ではエンジニア組織のことやプロダクトの技術戦略的なことを考えたり、ミーティングしたり採用活動したりタスクをお願いして回ったりなどを担当していますが、今日はそういうのとはなんの関係もないただの日常の話を書こうと思います。 ことの始まり 我が家では子どもの朝ごはんとして週に2,3回くらいの頻度でポケモンパンを買っています。 先日(2020/09/18 ~ 11/24) ポケモンパンについてるポイントを5点集めるとポケモンシールホルダーの抽選に1回応募できるキャンペーンがありました。(キャンペーン自体はすでに終了しています) いつも通りのペースでパンを買ってると何回か挑戦で

08/31 (2020): 投稿 08/31 (2020): 「畳み込みを一切使わない」という記述に関して、ご指摘を受けましたので追記いたしました。線形変換においては「チャネル間の加重和である1x1畳み込み」を実装では用いています。 08/31 (2020): 本論文で提案されているモデルの呼称に関して認識が誤っていたためタイトルおよび文章を一部修正しました。 言葉足らずの部分や勘違いをしている部分があるかと思いますが、ご指摘等をいただけますと大変ありがたいです。よろしくお願いします!(ツイッター:@omiita_atiimo) 近年の自然言語処理のブレイクスルーに大きく貢献したものといえば、やはりTransformerだと思います。そこからさらにBERTが生まれ、自然言語の認識能力などを測るGLUE Benchmarkではもはや人間が13位(2020/08現在)にまで落ちてしまっているほ

0. 忙しい方へ 完全に畳み込みとさようならしてSoTA達成したよ Vision Transformerの重要なことは次の3つだよ 画像パッチを単語のように扱うよ アーキテクチャはTransformerのエンコーダー部分だよ 巨大なデータセットJFT-300Mで事前学習するよ SoTAを上回る性能を約$\frac{1}{15}$の計算コストで得られたよ 事前学習データセットとモデルをさらに大きくすることでまだまだ性能向上する余地があるよ 1. Vision Transformerの解説 Vision Transformer(=ViT)の重要な部分は次の3つです。 入力画像 アーキテクチャ 事前学習とファインチューニング それぞれについて見ていきましょう。 1.1 入力画像 まず入力画像についてです。ViTはTransformerをベースとしたモデル(というより一部を丸々使っている)ですが、

要点 最先端機械学習モデル「Vision Transformer」に基づく、新たなレンズレスカメラの画像再構成手法を提案 提案した画像処理技術は高速に高品質な画像を生成できることを実証 小型・低コストかつ高機能であるため、IoT向け画像センシング等への活用に期待 概要 東京工業大学 工学院 情報通信系の潘秀曦(Pan Xiuxi)大学院生(博士後期課程3年)、陈啸(Chen Xiao)大学院生(博士後期課程2年)、武山彩織助教、山口雅浩教授らは、レンズレスカメラの画像処理を高速化し、高品質な画像を取得できる、Vision Transformer(ViT)[用語1]と呼ばれる最先端の機械学習技術を用いた新たな画像再構成手法を開発した。 カメラは通常、焦点の合った画像を撮影するためにレンズを必要とする。現在、IoT[用語2]の普及に伴い、場所を選ばず設置できるコンパクトで高機能な次世代カメラが

Innovative Tech: このコーナーでは、テクノロジーの最新研究を紹介するWebメディア「Seamless」を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。 米ミシガン大学、米フロリダ大学、電気通信大学による研究チームが発表した論文「You Can’t See Me: Physical Removal Attacks on LiDAR-based Autonomous Vehicles Driving Frameworks」は、自動運転車の周囲を検知するセンサーにレーザー光を物理的に照射して、選択的に障害物を見えなくする攻撃を提案した研究報告だ。偽の情報を注入するスプーフィング攻撃で自動運転車の物体検出モデルに影響を与え安全を脅かす。 自動運転車の知覚システムは、LiDARやカメラ、レーダーなどのセンサーを活用して、障害物回避やナビゲーション制

Innovative Tech: このコーナーでは、テクノロジーの最新研究を紹介するWebメディア「Seamless」を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。 スコットランドのHeriot-Watt University、フランスのUniversity Paul Sabatier、英University of Sussexによる研究チームが発表した論文「Selective neutralisation and deterring of cockroaches with laser automated by machine vision」は、ゴキブリを自動的に射殺できるデバイスを提案した研究報告だ。カメラでゴキブリを捉え、その位置にレーザー光を照射して殺傷する。

サッカーの試合でボールを追跡するはずのAIカメラ、審判のスキンヘッドを追いかけ生配信2020.11.03 08:00205,446 岡本玄介 不毛なストリーミングでした。 スコットランドのサッカーチームであるインヴァネス・カレドニアン・シッスルFCが、人間のカメラマンの代わりにAIを使ってボールを追いかけ、生配信するシステムを導入しました。ですがAIは、ボールではなく審判のスキンヘッドばかりを追跡することに…。 Video: Chuckiehands / YouTubeこれは対エアー・ユナイテッドFC戦で、シーズンパス保有者と試合のチケットを買った人たち限定で生配信された試合でした。強い逆光だったからなのか、ボールも審判の頭頂部も光り方が似ていますよね。 コロナ禍で無人カメラを導入したものの…この技術は、スコットランドのカレドニアン・スタジアムに設置された「Pixellotカメラ・システム

 Pythonで始める ドキュメント・インテリジェンス入門 / Introduction to Document Intelligence with Python
Pythonで始める ドキュメント・インテリジェンス入門 / Introduction to Document Intelligence with Python
ビジネス文書をデータ化し構造や内容を理解するアプリケーションはドキュメント・インテリジェンスと呼ばれ、画像処理や自然言語処理といった複数の要素技術を組み合わせて開発する必要があります。何が必要でどう実現すれば良いのかといった第一歩を、Pythonでの具体的な構築事例とともに紹介します。 https://2021.pycon.jp/time-table/?id=273795

 1ms 以下のリアルタイムオブジェクト検出/画像処理を目指して Goの配信サーバサイドで通知ぼかしを実装してみたこと - Mirrativ Tech Blog
1ms 以下のリアルタイムオブジェクト検出/画像処理を目指して Goの配信サーバサイドで通知ぼかしを実装してみたこと - Mirrativ Tech Blog
こんにちは ハタ です。 今回は以前iOSのクライアントサイドで実装していた通知ぼかし機能をサーバサイド(配信サーバ)上に再実装した事を書きたいなと思います 今回はかなり内容を絞りに絞ったのですが、長くなってしまいました、、 目次機能があったのでつけてみました、読み飛ばして読みやすくなった(?)かもしれません 目次 目次 通知ぼかし機能とは サーバサイド通知ぼかし プロトタイプの実装 苦労の始まり その1 画像処理速度 苦労の始まり その2 データ量 さらなる計算量の削減を求めて さらなる最適化へ Halide の世界へ 簡単な halide の紹介 苦労の始まり その3 いざ リリース リリースその後 We are hiring! 通知ぼかし機能とは 通知ぼかし機能は、ミラティブ上での配信中に写り込んでしまったiOSの通知ダイアログをダイアログの中身を見えないようにぼかし処理をしてあげる

自宅からリモートワークを行う際、ZoomやSkypeといったオンラインビデオ会議ツールを使用するケースがよくあります。オンラインビデオ会議ツールではウェブカメラを使って自分の顔を映しますが、アルゴリズムで別人になりきってオンラインビデオ会議に参加できるオープンソースのディープフェイクツール「Avatarify」が公開されています。 GitHub - alievk/avatarify: Avatars for Zoom and Skype https://github.com/alievk/avatarify This Open-Source Program Deepfakes You During Zoom Meetings, in Real Time - VICE https://www.vice.com/en_us/article/g5xagy/this-open-source-pro
ハッカーでありファッションデザイナーでもあるケイト・ローズ氏は、2019年8月8日(木)から8月11日(日)までラスベガスで開催されたセキュリティイベント「DEFCON27」で、「Adversarial Fashion(敵対的ファッション)」というオリジナルブランドを発表しました。Adversarial Fashionの服は自治体や政府が設置している監視システムに干渉するようなデザインとなっていて、監視カメラから個人の特定を防ぐことができるとのことです。 Adversarial Fashion https://adversarialfashion.com/ The fashion line designed to trick surveillance cameras | World news | The Guardian https://profile.theguardian.com/pr

悪用されても気付けない 「駅名は明かせませんが、約110の駅のコンコースなどに設置したおよそ5800台の監視カメラの一部に、顔認証機能を搭載しました。マスクをつけていても、不審者の顔を判別できる能力があります」(JR東日本広報) JR東日本が、ひっそりと「顔認証監視カメラ」を導入したことをご存じだろうか。駅利用者の顔と、登録されている犯罪容疑者や不審者の顔をリアルタイムで照合し、検知しているというのだ。 五輪開幕に合わせて、7月から導入していた。顔データの出元や最終的な情報提供先は「答えられない」と言うものの、警察とみて間違いない。 先月24日夜、東京・港区で男性に硫酸をかけた男は、JR品川駅から新幹線に乗って逃走した。男は28日にスピード逮捕されたが、この捜査にも顔認証監視カメラが活用されたとみられる。 捜査に役立つなら、問題ないと思うかもしれない。しかし、顔の画像を無差別に収集されるの

凸版印刷ではこの課題を解決するため、2015年から国文学研究資料館と共同研究を開始。古文書対応のAI-OCRの開発に取り組んできた。その中で「手元の古文書を手軽に読みたい」という一般利用者向けのサービスに対する多数の要望があり、今回のアプリ開発に至ったとしている。 凸版印刷は今後、2025年度までにAPI提供や関連事業を含め、一般利用者や教育機関、博物館・資料館、地方自治体などのサービス提供を拡大し、約3億円の売り上げを目指す。 関連記事 ライトを当てると文字や絵が現れるホログラム 凸版が開発 スマホライトで真贋判定 強い光(点光源)を当てると、立体的な画像が現れる新たなホログラム「イルミグラム」を凸版が開発。スマートフォンのライトなどで誰でも簡単・正確に真贋判定できる。 メタバースでのなりすましを防ぐ 3Dアバターの本人証明ができるセキュリティ基盤 凸版印刷が開発 凸版印刷が、メタバース

 日本語画像言語モデル「Japanese InstructBLIP Alpha」をリリースしました — Stability AI Japan
日本語画像言語モデル「Japanese InstructBLIP Alpha」をリリースしました — Stability AI Japan
Stability AIは日本語向け画像言語モデル「Japanese InstructBLIP Alpha」を一般公開しました。入力した画像に対して文字で説明を生成できる画像キャプション機能に加え、画像についての質問を文字で入力することで回答することもできます。 Japanese InstructBLIP Alpha「Japanese InstructBLIP Alpha」は、先日公開された日本語向け指示応答言語モデル「Japanese StableLM Instruct Alpha 7B」を拡張した、画像を元にしたテキストが生成されるモデルです。 「Japanese InstructBLIP Alpha」は、高いパフォーマンスが報告されている画像言語モデルInstructBLIPのモデル構造を用いております。少ない日本語データセットで高性能なモデルを構築するために、モデルの一部を大規模な

It’s 2022, and Teslas still aren’t stopping for children. pic.twitter.com/GGBh6sAYZS — Taylor Ogan (@TaylorOgan) August 9, 2022 今年実施されたテスラの走行テストの様子がTwitterに投稿され、10万いいねを超えるほどの話題になっています。 動画内ではテスラ Model3が走行中に、車両前方に配置された子どもに見立てた人形を検知して停止することができるかというテストの模様が撮影されています。 映像右側で同時にテスト走行しているレクサス RXがしっかり停止しているのに対し、Model3は人形を豪快に吹き飛ばしてしまいました。 「LiDAR」を搭載していないのが原因? 明るく見通しも良い状況にもかかわらず、Model3が人形の前で停止できなかったのは「子ども人形のクオ
![SNSで「10万いいね」レクサスとテスラの衝突安全テストの結果が衝撃すぎた | MOBY [モビー]](https://cdn-ak-scissors.b.st-hatena.com/image/square/75870a2e716aed144a439accc6b72cbced46e5bd/height=288;version=1;width=512/https%3A%2F%2Fcar-moby-cdn.com%2Farticle%2Fwp-content%2Fuploads%2F2021%2F02%2F09095752%2Ftesla_dealer_sign-1000x667.jpeg)
3人の若い米国人エンジニアは既存の部品、既存のアルゴリズム、3Dプリンターを使用し、画像照合航法で飛行する無人機を1日で作り上げてしまい、彼らは「ウクライナ政府系ファンド、特殊部隊、地上軍から直接声がかかっている」と明かした。 参考:How A Trio Of Engineers Developed A GPS-Denied Drone For Under $500 Theseusの無人機にはウクライナ政府系ファンド、特殊部隊、地上軍から直接声がかかっている米軍はロシアや中国の妨害してくるGPS信号への対応に苦慮しているが、3人の若いエンジニアは既存の部品、既存のアルゴリズム、3Dプリンターを使用し、画像照合航法で飛行する無人機(500ドル未満)を1日で作り上げてしまい、Aviation Weekは「彼らは低コストでGPSを代替する手段があると考えている」「この無人機の開発速度は国防総省が
全国の警察で3月から民間の防犯カメラやSNSの画像を顔認証システムで照合していた...... (写真とは関連がありません) REUTERS/Thomas Peter <全国の警察で3月から民間の防犯カメラやSNSの画像を顔認証システムで照合していたことを共同通信が報じた......> 前々回の記事「日本の警察は世界でも類を見ない巨大な顔認証監視網を持つことになるのか?」では、顔認証システムの拡充が進んでいることと、警視庁がリアルタイムで民間の監視カメラを一元管理し、顔認証システムで識別するシステムを持っていることをご紹介し、今後さらに拡充されていく可能性を指摘した。 それを裏付けるように9月12日に共同通信が全国の警察で3月から民間の防犯カメラやSNSの画像を顔認証システムで照合していたことを報じた(47NEWS、2020年9月13日)。日本の先を行くアメリカで顔認証システムの利用の見直

まるで透明マント。監視カメラでAIが認識しないアグリー・セーターが作られる2022.10.22 16:0090,468 岡本玄介 目立つ柄だけど社会的に消えます。 伝統的に冬になると欧米人が着る、ダッサい柄の「アグリー・セーター」。マイクロソフトも毎年新作をリリースし、音楽業界ではアイアン・メイデンやガンズ・アンド・ローゼズがオリジナルを作っていましたね。 さて、今年もそろそろアグリー・セーターの時期が到来しようという頃合いですが、ニューヨーク州にあるコーネル大学では、監視カメラでAIが認識しない「アグリー・セーター」が爆誕した模様。『ドラえもん』や『ハリーポッター』では物理的に消える「透明マント」がありましたが、こちらは社会的に透明人間になれる装備となっています。 検出オブジェクトの信頼度を下げる模様デカデカと印刷されている市場のカボチャみたいな模様は、機械学習システムが認証時に用いるス

社内勉強会での発表資料です。公開情報をもとにTeslaのコンピュータビジョン技術について調査したものです。Read less

 【独自】AIベンチャー企業の元取締役 33億円余りを着服か
【独自】AIベンチャー企業の元取締役 33億円余りを着服か
東京・千代田区の医療用のAI(人工知能)を開発するベンチャー企業の元取締役が、会社の口座からおよそ29億円を着服した疑いで警視庁に逮捕された。 元取締役は、33億円余りを着服したとみられている。 「エルピクセル」元取締役の志村宏明容疑者(45)は、2018年から2019年にかけて、会社の口座からおよそ29億円を着服した疑いが持たれている。 エルピクセルは、AIを活用した医療診断のソフトウエアを開発するなど、注目のベンチャー企業。 事件当時、志村容疑者は、経理担当者で会社の資金を1人で管理していて、着服した金の大半をFX取引に充てていたという。 警視庁は、志村容疑者があわせて33億円余りを着服したとみて余罪を調べている。

by Douglas Muth ゴキブリは多くの人にとって悩みの種なので、「もし自動でゴキブリを退治してくれるAIが登場したら是非使いたい」という人は多いはず。そんな人の夢を実現するAI搭載の自動レーザー砲台が開発されました。 なお、この記事にはゴキブリの映像や画像が掲載されるので、苦手な人は注意してください。 Full article: Selective neutralisation and deterring of cockroaches with laser automated by machine vision https://doi.org/10.1080/00305316.2022.2121777 Scientists Create AI-Powered Laser Turret That Kills Cockroaches https://www.vice.com/en/a

先日、革新的な画像の異常検知(SAA)が出てきました。 何やら革命的な臭いがする... SAMを使った異常検知手法https://t.co/wmwFcbULdq コードはこちらhttps://t.co/3npK3FhnEz pic.twitter.com/JDs30bEJyQ — shinmura0 (@shinmura0) May 22, 2023 本稿では、操作手順 & 触ってみた感想をご報告します。 特長 本題に入る前に、どこら辺が革新的なのかざっくり説明します。 ※ SAAの詳細は論文をご参照ください。 学習データは不要 通常、学習(正常)データを数百枚用意しますが、この手法では正常データを必要としません。 ドメイン知識を導入できる 予め、異常の傾向をプロンプトに入れることにより、異常の特徴をモデルに教えることができます。 二点目が特に大きく、今までの異常検知では、積極的に異常の傾

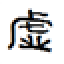 アボカドとアボガド、深層学習で識別 プロ並み精度誇る
アボカドとアボガド、深層学習で識別 プロ並み精度誇る
人工知能(AI)を使って果物のアボカドとアボガドを識別するシステムを、千葉電波大学の鰐梨教授らが開発した。専門家並みの精度で見分けることができるという。研究結果は英科学誌「フェノメノン」5月特大号に掲載された。 研究チームではアボカドとアボガドの写真をそれぞれ200万枚ずつ用意し、ディープラーニング(深層学習)という手法を用いて、AIにそれぞれの画像からアボカドとアボガドの特徴を見つけ出させた。学習後、判別前の果物を見せたところ、99.7%の確率でアボカドとアボガドをほぼ正しく区別した。 アボカドは脂肪分を多く含むことから「森のバター」と呼ばれる一方、アボガドは「森のマーガリン」と呼ばれ、アボカドの代用品として使われることが多い。プロであれば手触りや色の違いから容易に判別できるが、よく似た見た目をしているため、これまで一般の人には識別が難しかった。今後スマートフォン向けアプリなどへの応用を

ラズパイでAI画像認識環境構築 ひさしぶりにラズパイでディープラーニングしようと思ったら、色々変わっていたのでメモ。 追記:ラズパイ5に関しては以下記事参照ください。 前提 ハードウェアやソフトウェアの前提は以下です。 Raspberry Pi 4 Raspberry Pi OS(64-bit) with Desktop 2023-02-21(Bullseye) USBカメラ OSは64bitを使用します。32bitだとライブラリのバージョンが変わってくるのでこの記事のままだとインストールできませんので注意してください。 SDカードの書き込みやハードウェアのセッティングに関しては、以下記事参照ください。 また、上記記事では、カメラとしてRaspberry Pi カメラモジュールを使っていますが、Raspberry Pi OSがBullseyeになってから、使用するライブラリが変わった(Pi

Innovative Tech: このコーナーでは、テクノロジーの最新研究を紹介するWebメディア「Seamless」を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。 米マサチューセッツ工科大学(MIT)とMIT-IBM Watson AI Labの研究チームが開発した「Music Gesture for Visual Sound Separation」は、楽器を演奏する複数人の動きを深層学習で分析し、個々の楽器の音を分離する手法だ。ピアノ、フルート、トランペットなどの楽器を複数人で同時演奏した場合に、その映像から演奏者それぞれのメロディーを抜き出す。 映像解析ネットワークと視覚音声分離ネットワークの2つからなる「自己教師あり学習」を採用。映像解析ネットワークでは、人体のキーポイント18点、手のキーポイント21点を抽出。次に身体の動きと前後関係を統合し、

 【自動運転】信号機認識に挑む / 走行画像15,000枚のアノテーションとYOLOXモデルによる深層学習実践
【自動運転】信号機認識に挑む / 走行画像15,000枚のアノテーションとYOLOXモデルによる深層学習実践
こんにちは。TURING株式会社でインターンをしている、東京大学学部3年の三輪と九州大学修士1年の岩政です。 TURINGは完全自動運転EVの開発・販売を目指すスタートアップです。私たちの所属する自動運転MLチームでは完全自動運転の実現のため、AIモデルの開発や走行データパイプラインの整備を行っています。 完全自動運転を目指すうえで避けて通れない課題の一つに信号機の認識があります。AIが信号機の表示を正しく理解することは、自動運転が手動運転よりも安全な運転を達成するために欠かせません。信号機を確実に認識したうえで、周囲の状況を総合的に判断して車体を制御し、安全かつ快適な走行を実現する必要があります。 TURINGでは信号機の認識に取り組むため、15,000枚規模のデータセットを準備し、高精度なモデルのための調査・研究を開始しました。この記事ではデータセットの内製とその背景にフォーカスしつつ

 DeNAのマシンラーニングをささえるアノテーションシステム | BLOG - DeNA Engineering
DeNAのマシンラーニングをささえるアノテーションシステム | BLOG - DeNA Engineering
この記事では、DeNAでのコンピュータービジョン関連の機械学習のためのデータ生成処理方法について説明します。 主に、内製のアノテーションシステム「Nota」の開発とそのシステムと全体のMLワークフローに統合する方法について取り上げます。現在のソリューションに到達するため、私たちが行ったいくつかの決断、および解決しなければならなかった課題について説明します。 はじめまして、アラマ・ジョナタンです。現在DeNAのシステム本部で、分析推進部ソリューションエンジニアリンググループとAIシステム部MLエンジニアリンググループを兼務しているメンバーです。小さいチームでデータ関連の課題を解決するためのアプリケーションやツールの開発と運用をしています。 正確なデータを取得する問題 近年、AIには多くの進歩があり、それらの多くはコンピュータビジョンに関連しています。コンピュータは画像や動画にある内容を理解で

Innovative Tech: このコーナーでは、テクノロジーの最新研究を紹介するWebメディア「Seamless」を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。 米MetaのReality Labsの研究チームが開発した「Authentic Volumetric Avatars from a Phone Scan」は、スマートフォンで自撮りした短時間のスキャン画像から、本物そっくりの3D頭部アバターを生成するシステムだ。異なる視点やフォトリアリスティックな表情を表現し、高い忠実度で再現する。 現在、実在する人物のアバターを作成するためには膨大な人物データを取得する必要があり、そのデータを収集するには大規模なマルチビューキャプチャーシステムを必要とする。そのため軽量なデータキャプチャー、低遅延、許容できる品質でのアバター作成プロセスを自動化することが

 畳み込み+Attention=最強?最高性能を叩き出した画像認識モデル「CoAtNet」を解説! - Qiita
畳み込み+Attention=最強?最高性能を叩き出した画像認識モデル「CoAtNet」を解説! - Qiita
1. CoAtNetの解説 1.1 畳み込みとSAの復習 コンピュータビジョンで用いられている大きな仕組みに畳み込みとSelf-Attention(=SA)があります。畳み込みではEfficientNet、SAではViTが有名ですね。EfficientNetについてはこちらの拙著記事、ViTについてはこちらの拙著記事をご参照ください。CoAtNetでは、この畳み込みとSAの良いとこ取りをしたブロックを作ることが一番の目的になっています。畳み込みとSAの式を復習しておきましょう。ここでは畳み込みの中でもDW(=Depthwise)畳み込みを取り扱います。そして、本論文では分かりやすさを優先しているのか、式の細かいところ(SAにおけるqkvの埋め込みなど)はあえて排除しているように見えるので、理解しやすいです。 1.1.1 畳み込みの式 本論文では、畳み込みの中でもDW(=Depthwise)

 【2022年最新AI論文】画像異常検知AIの世界最先端手法「PatchCore」の論文を解説【CVPR 2022】 - Qiita
【2022年最新AI論文】画像異常検知AIの世界最先端手法「PatchCore」の論文を解説【CVPR 2022】 - Qiita
本日(2022/6/19)からアメリカのニューオーリンズで開催されているCVPR2022(2022/6/19-24)で、世界最先端の異常検知手法「PatchCore」が発表されました! CVPRはコンピュータビジョン分野のトップカンファレンスで、画像系AI研究の最難関の国際会議の一つです。ちなみに、昨年(CVPR2021)の採択率は23%。 PatchCoreは、外観検査(画像の異常検知)タスクで有名なデータセット「MVTecAD」でSOTA(State-of-the-Art)を達成しています。 この記事では、世界最先端の画像異常検知AIがどのような手法なのか、できるかぎり簡単にわかりやすく論文を解説したいと思います。 論文解説 タイトル/著者 Towards Total Recall in Industrial Anomaly Detection Karsten Roth, Latha

 USBに挿すだけ!Linuxで動く「M5Stack UnitV2」AIカメラの実力を試してみた! - paiza times
USBに挿すだけ!Linuxで動く「M5Stack UnitV2」AIカメラの実力を試してみた! - paiza times
どうも、まさとらん(@0310lan)です! 今回は、親指サイズの超小型ボディにLinuxを搭載し、さらにAI開発エディタやカメラなども詰め込んだ強力なカメラモジュールをご紹介します。 手持ちのパソコンにあるUSBに挿すだけですぐに起動し、専用の開発エディタを使ってAIカメラを試したりトレーニングをしたりなどが簡単にできるのが特徴です。 さらに顔認識、オブジェクト分類、トラッキング、カラー検出…など10種類以上の機能がすぐに利用できるうえ、Jupyter Notebookでモジュールを制御できるので便利です。 AIを活用したい人やIoT開発に興味がある人も含めて、ぜひ参考にしてみてください! ■「M5Stack UnitV2 AI カメラ」とは モニターやセンサー類などが全部入りの小型マイコンモジュール「M5Stack」シリーズで知られる中国のスタートアップ企業をご存知でしょうか。 同社が

 OpenCVの新しい顔検出をブラウザでも試してみる
OpenCVの新しい顔検出をブラウザでも試してみる
この記事はOpenCV Advent Calendar 2021の 23 日目の記事です。 はじめに 3 日目の記事で紹介されているように、OpenCV 4.5.4 では新しく顔検出/顔認識の API が実装されました。この記事ではこの顔検出 API をブラウザから呼んでみることにします。ブラウザから呼び出すにあたって、先にきちんとパフォーマンスを確認して使用する解像度を決めます。更に高速化のために SIMD とマルチスレッドを使った OpenCV の Wasm バイナリを作ります。その後、実用的な環境を想定して React のフロントエンドから呼び出すようにしてみます。ついでに WebRTC で実際に加工した画像が送信できることのデモまで行います。 OpenCV.js での新機能の扱い OpenCV.js で JavaScript から呼び出せる機能はホワイトリスト形式になっており、ビル

 誰でも機械学習を活用したWebアプリを開発できる「Teachable Machine」の完全チュートリアル大公開! - paiza開発日誌
誰でも機械学習を活用したWebアプリを開発できる「Teachable Machine」の完全チュートリアル大公開! - paiza開発日誌
どうも、まさとらん(@0310lan)です! 今回は、ブラウザ上で多彩な学習モデルを誰でも作れるWebサービスの使い方をチュートリアル形式でご紹介します。 面倒な設定や導入準備・高価な機材などは一切不要で、ノートパソコン1台あれば今すぐ始められる手軽さが魅力です。 最終的に簡単なJavaScriptで独自の学習モデルを活用できるので、機械学習を利用したWebアプリ開発にご興味ある方はぜひ参考にしてみてください! なお、paizaラーニングでは動画で学べる「Python×AI・機械学習入門講座」を公開しています。合わせてチェックしてみてください。 【 Teachable Machine 】 ■「Teachable Machine」の使い方 それでは、どのようなサービスなのか実際に使いながら見ていきましょう! まずはTeachable Machineのトップページを開いて【Get Starte

by Kevin Poh ある母娘がガールスカウトの集まりでクリスマスイベントの舞台を観劇しようとしたところ、母親だけ警備に呼び止められて会場から追い出されてしまいました。その理由について会場の運営会社は、母親が自社の訴訟を担当している弁護士事務所に所属する弁護士だからだと説明しました。 MSG’s Facial Recognition at Radio City Gets Girl Scout Mom Kicked Out – NBC New York https://www.nbcnewyork.com/investigations/face-recognition-tech-gets-girl-scout-mom-booted-from-rockettes-show-due-to-her-employer/4004677/ Girl Scout mom banned from Rad

2022/11/11 凸版印刷、明治期から昭和初期の手書き文字を解読する AI-OCRを日本で初めて開発

 画像認識と深層学習
画像認識と深層学習
日本ロボット学会 ロボット工学セミナー 第126回 ロボットのための画像処理技術 講演資料 https://www.rsj.or.jp/event/seminar/news/2020/s126.html 2012年の画像認識コンペティションILSVRCにおけるAlexNetの登場以降,画像認識においては深層学習,その中でも特に畳み込みニューラルネットワーク (CNN) を用いることがデファクトスタンダードとなった.CNNはクラス分類をはじめとして,物体検出やセグメンテーションなど様々なタスクを解くためのベースネットワークとして広く利用されてきている.本講演では,CNNの発展を振り返るとともに,エッジデバイスで動作させる際に重要となる高速化等,関連する深層学習技術の解説を行う. 1. クラス分類向けモデルについて 1.1. ILSVRCで振り返る進化の歴史 1.2. その他重要なモデル 1

 「お客様…」商品のパンを自動でスキャンしてくれるお店で買ったはずのないクリームパン2つがスキャン…原因はかわいい商品にあった!
「お客様…」商品のパンを自動でスキャンしてくれるお店で買ったはずのないクリームパン2つがスキャン…原因はかわいい商品にあった!
K_akiya @K_akiya @boat_10ku @bookdraught 兵庫の誇るレジです、よろしくお願いします。店員さんで学習データを補正していくので、認識されなくなる日がくるかもしれません。bakeryscan.com 2021-08-08 11:22:46 リンク BakeryScan(ベーカリースキャン) BakeryScan(ベーカリースキャン) トレイ上のパンの種類・値段をカメラで一括識別するシステムです。 画像識別技術をレジ精算に応用する世界初の試みで、 ベーカリーショップのレジ業務に革新をもたらします。 15 users 1

この記事は スプラトゥーン3の試合中に、やられる直前15秒の動画を自動作成するシステムを開発したので紹介します。 ここに至るまでの15秒の動画を試合中に自動作成します。 スプラトゥーン2の時に開発した、やられたシーン自動抽出システムは、時間がかかる スプラトゥーン2に引き続きスプラトゥーン3もやりこんでいますが、対面力に課題ありです。そこで、やられたシーンを録画で振り返りつつXマッチに潜っています。 その振り返りの効率化のため、スプラトゥーン2の時にプレイ録画から、やられたシーンを自動抽出するシステムを作りました。その様子はこちらの記事で解説しています。 スプラトゥーン2のプレイ動画から、やられたシーンだけをディープラーニングで自動抽出する Flutter Webで画像分類を行う(AutoML Vision, TensorFlow.js) しかしこのシステムには問題があります。試合が終わっ

j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


 グーグルレンズの「パソコンにコピー」が地味に便利だという話 - 世界のねじを巻くブログ
グーグルレンズの「パソコンにコピー」が地味に便利だという話 - 世界のねじを巻くブログ
 スマホにカメラついてるんだからOCRできるでしょという気持ち - Progate Tech Blog
スマホにカメラついてるんだからOCRできるでしょという気持ち - Progate Tech Blog
 Self-Attentionを全面的に使った新時代の画像認識モデルを解説! - Qiita
Self-Attentionを全面的に使った新時代の画像認識モデルを解説! - Qiita


 画像認識の大革命。AI界で話題爆発中の「Vision Transformer」を解説! - Qiita
画像認識の大革命。AI界で話題爆発中の「Vision Transformer」を解説! - Qiita
 機械学習の進化が、「レンズ」というカメラの当たり前を覆す 次世代イメージセンシング・ソリューション開発を加速
機械学習の進化が、「レンズ」というカメラの当たり前を覆す 次世代イメージセンシング・ソリューション開発を加速
 自動運転車の視界から“人だけ”を消す攻撃 偽情報をLiDARに注入 電通大などが発表
自動運転車の視界から“人だけ”を消す攻撃 偽情報をLiDARに注入 電通大などが発表
 ゴキブリを自動で見つけレーザーで殺す装置 数万円で自作も可能
ゴキブリを自動で見つけレーザーで殺す装置 数万円で自作も可能
 サッカーの試合でボールを追跡するはずのAIカメラ、審判のスキンヘッドを追いかけ生配信
サッカーの試合でボールを追跡するはずのAIカメラ、審判のスキンヘッドを追いかけ生配信
 ZoomやSkypeでリアルタイムに他人になりすませるオープンソースのディープフェイクツール「Avatarify」
ZoomやSkypeでリアルタイムに他人になりすませるオープンソースのディープフェイクツール「Avatarify」
 「監視カメラの画像認識をだます服」をハッカー兼ファッションデザイナーが発表
「監視カメラの画像認識をだます服」をハッカー兼ファッションデザイナーが発表
 「硫酸男」スピード逮捕のウラで…実はJRが「顔認証カメラ」を導入していた(週刊現代) @moneygendai
「硫酸男」スピード逮捕のウラで…実はJRが「顔認証カメラ」を導入していた(週刊現代) @moneygendai
 古文書を解読できるスマホアプリ 凸版印刷が開発 くずし字対応AI-OCRを活用
古文書を解読できるスマホアプリ 凸版印刷が開発 くずし字対応AI-OCRを活用
 SNSで「10万いいね」レクサスとテスラの衝突安全テストの結果が衝撃すぎた | MOBY [モビー]
SNSで「10万いいね」レクサスとテスラの衝突安全テストの結果が衝撃すぎた | MOBY [モビー]
 若い米国人エンジニア、500ドル未満でGPSに依存しない無人機を1日で開発
若い米国人エンジニア、500ドル未満でGPSに依存しない無人機を1日で開発
 日本の警察は、今年3月から防犯カメラやSNSの画像を顔認証システムで照合していた
日本の警察は、今年3月から防犯カメラやSNSの画像を顔認証システムで照合していた
 まるで透明マント。監視カメラでAIが認識しないアグリー・セーターが作られる
まるで透明マント。監視カメラでAIが認識しないアグリー・セーターが作られる
 Teslaにおけるコンピュータビジョン技術の調査
Teslaにおけるコンピュータビジョン技術の調査
 レーザーでゴキブリを自動ロックオンして焼き殺すAI搭載タレットが登場
レーザーでゴキブリを自動ロックオンして焼き殺すAI搭載タレットが登場
 【速報】次世代の外観検査!?プロンプトを駆使した異常検知 - Qiita
【速報】次世代の外観検査!?プロンプトを駆使した異常検知 - Qiita
 最新Raspberry Pi OS(Bullseye)のAI画像認識環境構築方法
最新Raspberry Pi OS(Bullseye)のAI画像認識環境構築方法
 混ざった楽器の音を演奏者の動きで分離 米MITなど研究
混ざった楽器の音を演奏者の動きで分離 米MITなど研究
 iPhoneの自撮りで本物そっくりな動く3Dリアルアバター 米Metaが技術開発
iPhoneの自撮りで本物そっくりな動く3Dリアルアバター 米Metaが技術開発
 顔識別技術でガールスカウトの母親が「裁判中の弁護士事務所の弁護士」だと判明しイベント会場から追い出されてしまう
顔識別技術でガールスカウトの母親が「裁判中の弁護士事務所の弁護士」だと判明しイベント会場から追い出されてしまう
 凸版印刷、明治期から昭和初期の手書き文字を解読するAI-OCRを日本で初めて開発
凸版印刷、明治期から昭和初期の手書き文字を解読するAI-OCRを日本で初めて開発
 スプラトゥーン3で、やられたシーンをOBSのリプレイバッファで自動保存する - Qiita
スプラトゥーン3で、やられたシーンをOBSのリプレイバッファで自動保存する - Qiita
 tmchu.dreamlog.jp
tmchu.dreamlog.jp digital.asahi.com
digital.asahi.com nemotoplant.com
nemotoplant.com ameblo.jp/windy1255
ameblo.jp/windy1255 konodaichi.com
konodaichi.com tamikiti67.hatenablog.com
tamikiti67.hatenablog.com